手搓神经网络系列之——实现SGD优化器
AI摘要Kimi Chat
本文,我们来实现一个SGD优化器,用以梯度更新。有了前面的铺垫,这个SGD优化器的实现将超乎想象的容易。
本系列全部代码见下面仓库:
引用站外地址,不保证站点的可用性和安全性

autograd-with-numpy
GitHub
如有算法或实现方式上的问题,请各位大佬轻喷+指正!
前文中,我们实现了Module类,它拥有一个parameters方法,返回一个包含模型中所有可训练参数的生成器,我们可以调用该方法,取得一个模型中所有可训练参数的列表。
params = list(model.parameters())考虑到优化器种类比较多,我们先实现一个优化器的基类:Optimizer,它需要传入所有优化器必备的参数,我能想到的有:可训练参数列表、学习率、一阶正则化系数、二阶正则化系数。另外,它需要实现所有优化器的共有方法,我能想到的有:正则化、梯度清零。
下面给出我实现的优化器基类代码:
class Optimizer(object):
def __init__(self, params: Module.parameters, lr=1e-3, alpha=0., weight_decay=0.):
assert lr >= 0., f"Invalid learning rate: {lr}"
assert alpha >= 0., f"Invalid alpha value: {alpha}"
assert weight_decay >= 0., f"Invalid weight_decay value: {weight_decay}"
self.params = list(params)
self.lr = lr
self.alpha = alpha
self.weight_decay = weight_decay
@nptorch.no_grad()
def _regularization(self):
if self.alpha > 0.:
for p in self.params:
p.grad += self.alpha * (2. * (p.data > 0.).astype(np.float32) - 1.)
if self.weight_decay > 0.:
for p in self.params:
p.grad += self.weight_decay * p.data
def zero_grad(self):
for p in self.params:
p.grad.zero_()- 初始化函数,
alpha为一阶正则化系数,weight_decay为二阶正则化系数。函数中首先对输入的参数进行了校验,然后将生成器类型的params参数转为list。 _regularization方法是正则化操作,正则化相当于在所有可训练参数的梯度上额外增加了一项,我们通过这个正则化操作提前把梯度加上。zero_grad方法,用于清空可训练参数的梯度,这里我为Tensor类提供了一个zero_方法,用于将自身的数据清零。
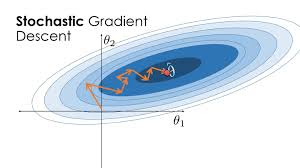
接下来,我们基于这个基类,来实现SGD优化器。SGD优化器多出来一个参数为动量(momentum),其值介于$[0, 1)$半开区间。动量法是模拟小球在山间的运动过程,用以帮助SGD突破局部极小值,加速向全局最小值收敛。
设动量系数为$\gamma$,学习率为$\eta$,则基于动量法的参数更新公式如下:
基于上述公式,我们可以为SGD加入一个列表v用以$V$值的动态更新,并实现step方法。以下是我实现的SGD代码。
class SGD(Optimizer):
def __init__(self, params: Module.parameters, lr=1e-3, momentum=0., alpha=0., weight_decay=0.):
"""
SGD优化器
@param params: 需要优化的模型参数
@param lr: 学习率
@param momentum: 动量
@param alpha: L1正则化系数
@param weight_decay: L2正则化系数
"""
super(SGD, self).__init__(params, lr, alpha, weight_decay)
assert 0. <= momentum < 1., f"Invalid momentum value: {momentum}"
self.momentum = momentum
if momentum != 0.:
self.v = [0.] * len(self.params)
@nptorch.no_grad()
def step(self):
self._regularization()
if self.momentum > 0.:
for i, p in enumerate(self.params):
self.v[i] = self.momentum * self.v[i] - self.lr * p.grad.data
p.data += self.v[i]
else:
for p in self.params:
p.data -= self.lr * p.grad.data有了SGD优化器,我们就可以用它来训练模型了。后面一篇文章,我们将实现一个最简单的LeNet,用在深度学习领域的入门数据集MNIST,以实现手写数字的识别,以此对我们自己写的神经网络模型进行最终的检验。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 逸风亭!
- V me 50!
- Alipay is also ok~


相关推荐


评论
TwikooGiscus