
Ubuntu开机黑屏左上角光标不闪烁的解决办法
不小心装错了显卡驱动,导致Ubuntu系统开机黑屏。这种情况很有可能是装驱动的时候生成了新的系统内核,然后GRUB默认用新内核启动,而新内核有问题导致的。
遇到这种情况时,可以重启,进入GRUB界面时,选择Advanced options for Ubuntu,如果显示内容和下图类似,那么可以通过删除错误内核的方式,解决此问题。
图片中显示有两个Linux内核,前面的5.4.0-87是默认内核,但无法正常启动,因此该内核是有问题的,我们可以选择第三个5.4.0-86,应该可以正常启动起来。
在正常启动后,使用命令删除一些相关的包,然后删掉/boot路径下与5.4.0-87内核相关的所有内容,最后更新一下GRUB即可,命令如下:
sudo apt remove *5.4.0-87
sudo update-grub
再次重启,发现已经可以正常启动了!

Python实现12306购票(四)
该系列最后一篇文章,来实现提交订单(购票),不过:不支持付钱。
本文只涉及一个函数confirm_single_for_queue,位于此文件
提交订单在前面余票查询完成后,我们就可以真正地提交订单了,提交订单的请求如下:
POST https://kyfw.12306.cn/otn/confirmPassenger/confirmSingleForQueue
参数:
passengerTicketStr
oldPassengerStr
randCode
purpose_codes
key_check_isChange
leftTicketStr
train_location
choose_seats
seatDetailType
is_jy
is_cj
whatsSelect
roomType
dwAll
_json_att
REPEAT_SUBMIT_TOKEN
encryptedData
前面几个参数(从randCode到train_location)都与前一篇文章一样,来自于ticketInfoForPassengerForm这 ...

Python实现12306购票(三)
前面文章已经成功实现了登录,接下来就可以愉快地购票了,但在购票之前,我们需要知道12306处理订单的逻辑。
本文相关代码见此文件
点击预定获取车票信息我们在网页端订票时,首先通过查票系统查到自己想要的票,然后点击右边的“预定”:
然后会跳转到这个链接:
https://kyfw.12306.cn/otn/confirmPassenger/initDc
在此网页中可以添加订单与提交订单,最终实现购票。
但我们没有为上面的链接提供任何关于车票信息的参数,网页是如何知道我们选择的是哪张车票呢?
其实这是因为我们的浏览器会话在访问上面的链接之前还无意间发起过一个包含了车票信息的请求。
我们在Network里抓包,可以发现,在点击“预定”按钮后产生了一条名为submitOrderRequest的包,如下:
它提交的表单信息中含有车票相关的信息,把它写下来如下:
POST https://kyfw.12306.cn/otn/leftTicket/submitOrderRequest
参数:
参数
说明
secretStr
一串奇怪的字符串
train_date
发车日期(格式% ...

Python实现12306购票(二)
这篇文章来分享一下我实现12306登录的过程。
注:本文提到的RAIL_DEVICEID、RAIL_EXPIRATION参数在目前的版本中已经不需要了。
本文相关代码见此文件
12306的登录方式12306网页端支持以上两种登录方式,点击立即登录,出现以下验证信息:
第一个滑块,感觉破解起来难度很大,先放一放,还有个短信验证,但经过我的尝试,该验证方式有每日次数限制,感觉不太爽,最舒服的登录方式当属扫二维码登录,因此我研究了一下二维码登录12306的机制。
两种登录的途径二维码登录SMS验证码登录打开浏览器的f12开发者界面进行抓包,然后点击二维码登录,在网络正常的情况下,可以成功抓到一条名为create-qr64的数据包,明显就是二维码的来源,打开看一下:
可见二维码图片是以base64编码方式发送到客户端的,同时发送过来的还有一个重要的参数:uuid,作为临时凭证唯一标识了每一个二维码。
该请求详细情况如下:
POST https://kyfw.12306.cn/passport/web/create-qr64
参数:
参数
值
appid
otn
请求 ...

Python实现12306购票(一)
12306号称反爬最强的网站,因此我小试了一下,花了几天时间,实现了脚本购票,并做了一个简单的cmd客户端。
本项目只是实现了通过发送数据包请求来实现购票,并未优化抢票流程、速度,仅供娱乐与学习。
从本文开始,将陆续分享几篇爬12306网站的经验和思路。首先,我并没有用到诸如selenium这类可以快速简化问题但运行速度极慢的模拟浏览器爬虫,而是用了requests库的无头请求方式。BTW,本文只分享思路,而不会涉及很多代码,若想查看完整代码,可访问下面仓库:
引用站外地址,不保证站点的可用性和安全性
12306
GitHub
本文将分享其中最容易实现的功能:查询票务信息
本文相关代码见此文件
众所周知,即使你没有登录,也可以在12306网站上查询票务信息,并且在爬取过程中需要注意的地方并不多,因此我觉得这个功能是最容易实现的。
分析查票请求首先,打开12306查票主页面https:/ ...

中科大羽毛球场预约小程序脚本
更新于2022-10-7:鉴于羽毛球馆预约平台已经更换,本文所述方法已失效。新平台也太难爬了。。。调用wx.login获取code以及后面调用wx云函数获取noise参数靠抓包似乎不大可行(我的水平太菜了),如果您有相关经验,可以在底下留言或者联系我。
前面已经爬过了蜗壳的健康打卡系统,因为该系统以网页作为前端,可以在浏览器直接打开分析,前端代码也没有出现复杂的逻辑,因此爬起来并没有遇到什么阻力。
中校区体育场、游泳馆等建筑落成并开放后,吸引了一众学生前往进行各种体育活动,其中,位于综合馆的羽毛球场十分火爆,容易抢不到预约,因此我决定写个脚本来实现羽毛球场抢预约。
小程序名为“中国科大中校区体育中心”,其主界面如下所示:
拿到这么一个界面,我第一反应就是看一下主页的链接,结果发现它前端并不是h5,而是一个货真价实的小程序,不是用浏览器打开的,因此也就没有办法直接获取它的主页链接,基于此,我们需要一款抓包软件来直接分析其API接口。
软件介绍抓包软件可以使用Fiddler、Charles等,这里我使用了Charles。Charles是一款付费软件,但可以被轻松破解,破解方法我这里就不介 ...

用Python实现中科大健康打卡脚本
新冠疫情期间,学校规定假期必须每天进行健康打卡,汇报自身各项情况,在开学前未中断且打满14天才可申请返校,而开学后虽然不管,但原则上仍需每天打卡、每周报备。
打卡?这辈子不可能手动打卡的,我决定写一个爬虫脚本来自动打卡。
登录首先来分析一下打卡的登录逻辑:
打卡平台的网址是https://weixine.ustc.edu.cn/2020/home。
点进去发现其跳转到了https://weixine.ustc.edu.cn/2020/login,其中有一条“统一身份认证登录”。
点击“统一身份认证登录”,页面跳转到https://passport.ustc.edu.cn/login?service=https%3A%2F%2Fweixine.ustc.edu.cn%2F2020%2Fcaslogin,这是打卡平台在科大统一身份认证平台注册的CAS身份认证服务链接,我们在此需要输入科大Passport的账号密码,即可登录。
因此,从这个逻辑可以得到,我们可以向上面第3点中的CAS身份认证URL发送包含登录信息的POST数据包,来实现登录。不过,事实上只要我们先在会话中登录了https ...

Lede(Stones)固件下游设备无法获取公网IPv6地址的解决方法
前文曾提到过OpenWrt通过relay(中继)模式使得自身以及下游设备从ISP运营商获取原生公网IPv6的方法,但我在Phicomm K3路由器上刷了lede(Stones)固件后,按照相同的配置方法竟无法让下游设备获取到公网IPv6地址。
首先,家里的网络结构是通过一台光猫进行双栈拨号上网,路由器WAN口接到光猫LAN口,家里所有设备接入路由器的无线网络来进行上网。按照前面文章的方法进行配置后,我遇到的情况如下:
路由器的WAN口确实通过光猫获取到了两个2409开头的IPv6 Global地址
接入无线网络的设备均无法获取IPv6 Global地址,仅有一个Link-Local地址
路由器虽有IPv6 Global地址,但无法ping通任何外网的IPv6地址
接下来就是漫长的问题排查之路。
首先我用电脑直接连接了光猫的WiFi,发现电脑可以获取到两个IPv6 Global地址,且可以ping通外网的IPv6,这说明光猫的配置以及拨号都没有问题。
接下来登录路由器的命令行,查看IPv6网关的分配情况:
fe80::1正是光猫LAN口的IPv6 Link-Local地址,看上去好像 ...

Phicomm K3刷OpenWrt
之前入手的Redmi AC2100在寝室用尚可,但在面积较大的环境里出现了信号较弱的现象(后来我才了解到小米路由器的口碑不大行)。
另外,Redmi AC2100在性能上存在瓶颈(只有128MB内存,稍微跑点其他程序,内存就吃紧了),因此我入手了标题中这款Phicomm K3路由器,其具有512MB的超大内存、拥有USB接口且可以自由刷机。
图片中就是这款Phicomm K3路由器,外型十分独特。
一开始,我只是想简简单单刷个OpenWrt,但简单了解一下之后,我发现这款路由器涉及到的固件版本之多,是我始料未及的,我花了点时间做了功课后总结得出,一共有以下五种固件:
官方原版固件(原厂)
官方改装版固件(官改)
官方root固件(官root)
OpenWrt/lede
Merlin
而其中,每一种固件又分好几种版本,不同的版本的特性也有所不同,刷机的方法也有区别,不过好在,有一位大佬早就帮忙总结好了:
引用站外地址,不保证站点的可用性和安全性
斐讯K3 官方 ...
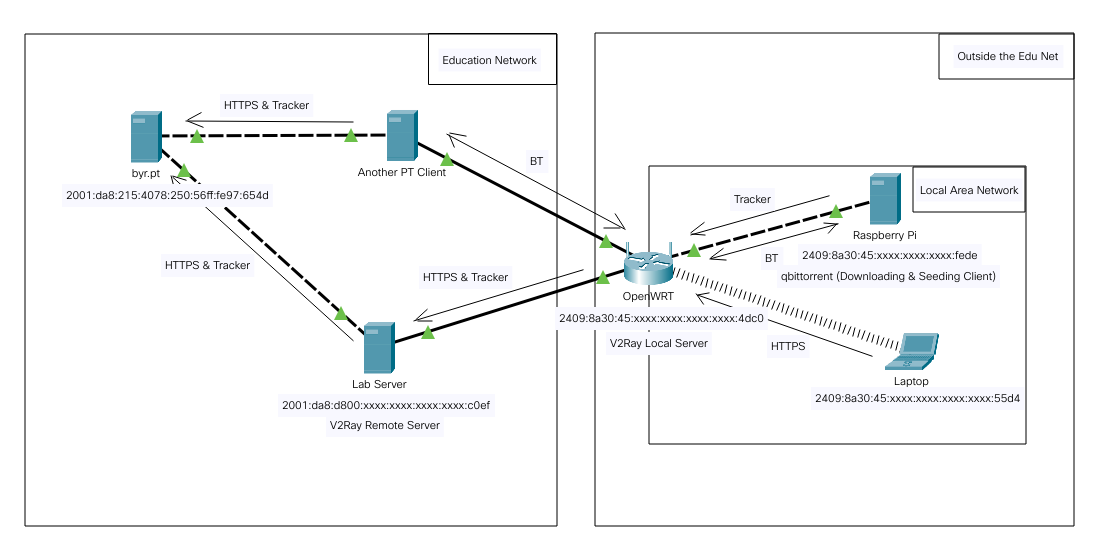
如何在校外使用北邮人PT站
两年前在朋友的邀请下加入了北邮人PT站(bt.byr.cn,最近更改了域名为byr.pt),该站点是一个纯IPv6站,且屏蔽了国内三大运营商的IPv6地址,在国内只能通过教育网来访问
北邮人PT站资源丰富,相当实用。为此,我还特意在树莓派上搭建了一个BT资源下载站,用于下载资源以及长期做种。
研二宿舍搬迁,我为方便起见去外面租了房子,这就导致我接不上教育网,也就没有办法访问站点了。在探明了访问不了的原因后,我就想到是不是可以通过科学上网的方法翻进教育网,从而访问到站点。恰好我在学校实验室里有一台服务器,它是接入教育网的,因此可以用它来做正向代理去请求站点,实现从非教育网访问到北邮人站点。
由于我在实验室的服务器并没有公网IPv4地址,但拥有IPv6 Global地址,因此这要求客户端也拥有IPv6 Global地址以与服务器通信,不过基于目前国内运营商都已经支持了双栈拨号,这并不是问题。
考虑到大部分人没有这种接入教育网的服务器,还有另外一种更容易满足的选择,即一台拥有海外IPv6地址的VPS。说起这个,就必须推广一下Vultr这个我曾经用过很长一段时间的平台了,这个平台的VPS可添加 ...
手搓神经网络系列之——训练模型(完结篇)
本文是此系列的完结篇,我们将用自己实现的神经网络来训练一个识别手写数字的模型。训练代码包含一些我前面没有提到的东西,例如数据变换函数等,不过这些都并非本系列的重点,实现起来也很简单粗暴,故不再细说!
本系列全部代码见下面仓库:
引用站外地址,不保证站点的可用性和安全性
autograd-with-numpy
GitHub
如有算法或实现方式上的问题,请各位大佬轻喷+指正!
本文的内容对于深度学习领域的学习者而言应该是非常熟悉的基本操作,所以我基本只贴代码了,望谅解。
注:本文模型结构与上图并不符,上图只是用来充个数的
我们先给出数据载入函数与数据类:
def load_mnist(img_path, label_path):
with open(label_path, 'rb') as label:
struct.unpack('>II', label.rea ...
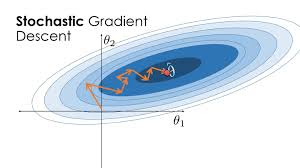
手搓神经网络系列之——实现SGD优化器
本文,我们来实现一个SGD优化器,用以梯度更新。有了前面的铺垫,这个SGD优化器的实现将超乎想象的容易。
本系列全部代码见下面仓库:
引用站外地址,不保证站点的可用性和安全性
autograd-with-numpy
GitHub
如有算法或实现方式上的问题,请各位大佬轻喷+指正!
前文中,我们实现了Module类,它拥有一个parameters方法,返回一个包含模型中所有可训练参数的生成器,我们可以调用该方法,取得一个模型中所有可训练参数的列表。
params = list(model.parameters())
考虑到优化器种类比较多,我们先实现一个优化器的基类:Optimizer,它需要传入所有优化器必备的参数,我能想到的有:可训练参数列表、学习率、一阶正则化系数、二阶正则化系数。另外,它需要实现所有优化器的共有方法,我能想到的有:正则化、梯度清零。
下面给出我实现的优化器基类代码 ...

手搓神经网络系列之——封装Module类及其子类
从这篇文章开始,我们来着手实现模型的优化功能,本文主要来实现第一步:Module类以及其具体子类的实现,在实现的过程中,我参考了一部分PyTorch的相关源码。
本系列全部代码见下面仓库:
引用站外地址,不保证站点的可用性和安全性
autograd-with-numpy
GitHub
如有算法或实现方式上的问题,请各位大佬轻喷+指正!
熟悉PyTorch的朋友都知道,Module类是作为神经网络各种模块(例如线性层、卷积层等)的基类而存在的,实现它是为了更方便地实现与PyTorch类似的神经网络模块功能。
首先,我们需要定义一个可训练参数类:Parameter。定义比较容易,直接继承前面定义的Tensor,并修改一些参数即可:
class Parameter(Tensor):
def __init__(self, tensor: Tensor):
if not ...
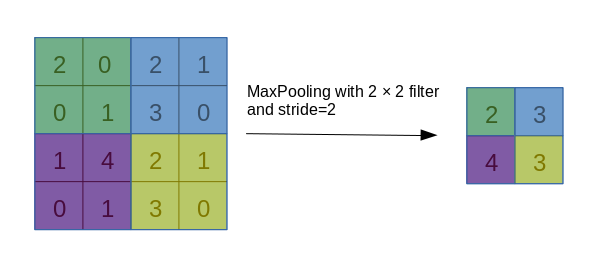
手搓神经网络系列之——池化与BN层
结束了本系列最硬核的卷积反向传播部分,从这篇文章开始,将进入比较软核的内容,本文来介绍池化运算和BN层的正反向传播。
本文涉及到的数学公式比较多,网页前端渲染会比较慢,烦请耐心等待和阅读。
本系列全部代码见下面仓库:
引用站外地址,不保证站点的可用性和安全性
autograd-with-numpy
GitHub
如有算法或实现方式上的问题,请各位大佬轻喷+指正!
池化池化运算(Pooling),是一种对数据的采样方式,通过减小数据的分辨率尺寸来加速运算,其本质是信息完整性与运算速度的妥协。最常用的池化操作即最大池化(MaxPooling),过程如下图所示:
一般而言,以上面这种池化核尺寸为2、步长为2的池化操作最为常用。还有一种平均值池化,则是把每一块的最大值运算换成平均值运算。
前向传播池化与卷积很像,因此前向传播时,我们可以利用前面卷积时用到的split_by_strides函数, ...
手搓神经网络系列之——卷积运算的反向传播(二)
前一篇文章中我们简单推导了卷积运算的梯度传播公式,本文将通过代码实现卷积反向传播的过程。本文代码主要位于nn/conv_operations.py文件,反向传播代码位于autograd/backward.py文件。
本系列全部代码见下面仓库:
引用站外地址,不保证站点的可用性和安全性
autograd-with-numpy
GitHub
如有算法或实现方式上的问题,请各位大佬轻喷+指正!
首先揭秘前面提到的dilate操作,在卷积步长$S>1$时,我们在对卷积核$W$计算梯度$\delta_W$时,需要将$\delta_Z$进行所谓的dilate操作,下图为$S=2$时,需要进行的dilate操作示意图。
事实上,dilate操作就是在相邻的行(列)之间插入一定行(列)数的0,通过推导可以知道,每两行(列)之间插入0的行(列)数=$S-1$。
另外,我们在反向传播的时候需要讨论一 ...
手搓神经网络系列之——卷积运算的反向传播(一)
前面写了整整三篇文章讨论了卷积运算的正向传播,本文将进入卷积运算的反向传播部分,将涉及到一些简单的数学公式推导(与其说是推导,不如说是瞪眼法+直接写结论),都是最简单的线性函数,不必裂开。
本系列全部代码见下面仓库:
引用站外地址,不保证站点的可用性和安全性
autograd-with-numpy
GitHub
如有算法或实现方式上的问题,请各位大佬轻喷+指正!
我们以下面简单的卷积过程为例,推导卷积运算的梯度传播式:
我们将上面的卷积过程展开写出来,得到下面4个方程:
\left\lbrace\begin{aligned}z_{00}=x_{00}w_{00}+x_{01}w_{01}+x_{10}w_{10}+x_{11}w_{11}\\z_{01}=x_{01}w_{00}+x_{02}w_{01}+x_{11}w_{10}+x_{12}w_{11}\\z_{10}=x_{10} ...
手搓神经网络系列之——卷积运算的正向传播(三)
前文介绍了一种卷积运算的骚操作——img2col,但仍不是十分满意,本文将介绍另一种卷积的骚操作——as_strided。
用as_strided结合tensordot函数,实现的卷积运算甚至不需要在Python中做for循环,达到了极致的简洁美。
本系列全部代码见下面仓库:
引用站外地址,不保证站点的可用性和安全性
autograd-with-numpy
GitHub
如有算法或实现方式上的问题,请各位大佬轻喷+指正!
本文很长,希望你忍一下。
一些你需要了解的前置知识Numpy数组在内存中的存储我们首先介绍numpy数组在内存里存储方式。
众所周知,numpy中的数据类型都有其对应的内存占用,例如int64与float64都会占用8个byte的内存空间,bool类型占用1个byte等。具体请移步官方文档进行查看。
除此以外,我们还需要知道numpy数组的元素在内存中的排列顺序。如果 ...
手搓神经网络系列之——卷积运算的正向传播(二)
本文仍然讲解卷积运算的正向传播方法,前一篇文章中我们用for循环将卷积运算实现了一下,重点关注的是卷积的运算过程,而并未对其进行优化,本文将引入一种相对比较容易想到的卷积优化方法——img2col。
本系列全部代码见下面仓库:
引用站外地址,不保证站点的可用性和安全性
autograd-with-numpy
GitHub
如有算法或实现方式上的问题,请各位大佬轻喷+指正!
img2col方法介绍“img2col太简单了,我早就会了!”→直接进入卷积正向传播的第三篇文章。
img2col的目的是将繁杂的卷积过程转化为一次矩阵乘法运算,从而大大降低运算量,为了减少语言上的琐碎描述,下面直接以图片来展示过程,先祭出前面文章里卷积过程的动图:
注意到,卷积核每次在图像上移动时,都会与对应区域做一个内积运算(元素间相乘再求和),这一过程与矩阵乘列向量的过程十分类似,因此就有了以下操作:
上面演示 ...
手搓神经网络系列之——卷积运算的正向传播(一)
在传统图像处理中,卷积占据了非常大的比重,在Transformer出来之前,卷积神经网络(CNN)也长期霸榜CV领域的深度学习任务。
而虽然现在有Transformer等利器,但卷积神经网络仍是众多场景任务中的一把手,尚未有被取代的迹象。
本系列全部代码见下面仓库:
引用站外地址,不保证站点的可用性和安全性
autograd-with-numpy
GitHub
如有算法或实现方式上的问题,请各位大佬轻喷+指正!
为啥要单独讲卷积以下,就是卷积神经网络的示意图:
…不好意思放错了,下面这个才是:
卷积运算因为其不同于其他张量运算的规则以及其重要程度,被我单独拎出来讲,还有一个原因是,卷积虽然不难理解,但其反向传播很容易掉脑细胞。不过,卷积的正反向传播都有一些trick,使用了trick后,算对只是基本操作了,还能让卷积和反向传播的速度非常的快(使用trick后的卷积运算已经和CPU版 ...

手搓神经网络系列之——梯度反传函数具体怎么写?(三)
本文将介绍几种特殊张量运算的反向传播。
众所周知,神经网络中涉及到关于张量的运算不止于加减乘除,还有最大最小值运算等,与常规运算不同,有些特殊运算在数学上甚至是不可微的,但即便如此,我们仍然需要将梯度反传回去。
本系列全部代码见下面仓库:
引用站外地址,不保证站点的可用性和安全性
autograd-with-numpy
GitHub
如有算法或实现方式上的问题,请各位大佬轻喷+指正!
本文将介绍Swapaxes运算、Max运算的反向传播。其他特殊运算,就不再一一列举!(主要太懒了)
Swapaxes与矩阵的转置类似,张量运算swapaxes的目的就是交换某两个轴,其定义为:
def swapaxes(self, axis1, axis2):
...
axis1、axis2即为交换的两个轴的序号。稍微想一想容易知道,怎么换过去的就怎么换回来,反传回去的梯度应该就是把梯度的axis ...